Overview
The AI system implements artificial intelligence 'agents' to compete against a human player in a game of Spelldawn. This page provides an technical overview of the architecture of the AI system on the server.
The Agent Trait
An AI agent implementation must implement the
Agent
trait, which provides the pick_action() function to allow the
agent to select a game action to perform given a game state. The agent is
provided an AgentConfig which contains information such as a
deadline by which the agent is expected to return an action.
The AgentData Struct
The Agent trait should almost always be implemented by using the
AgentData
struct. This data structure pairs together a few reusable pieces that make up
the 'standard model' of AI behavior:
- The agent's name
- A State Predictor to identify possible game states
- A State Combiner to merge together state predictions
- A Selection Algorithm to pick an action in a given game state
- A State Evaluator to analyze the value of game states
These pieces work together to provide an agent response, as described next.
AI Building Blocks
The standard dataflow for resolving a pick_action() function call
goes through each of these systems in turn as illustrated here:
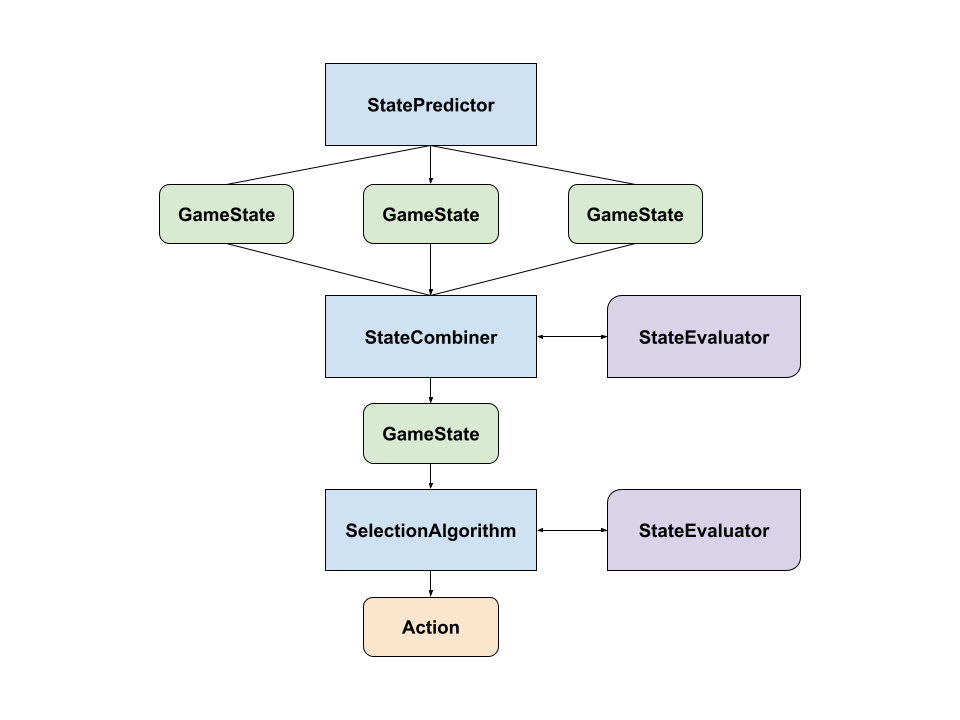
StatePredictor
Spelldawn is a game with hidden information. The state of things like the
opponent's face-down cards can significantly change the decision-making
process of an AI implementation. In order to represent this, the
StatePredictor
type takes the actual canonical game state and returns an iterator over
possible game states which represent the agent's limited information
about the world.
StatePredictor implementations should typically censor any non-public information from the input game state. They can also optionally implement prediction heuristics to derive possible game states, e.g. inferring the identity of face-down cards based on opponent behavior.
The simplest StatePredictor is the 'omniscient' predictor which simply returns the canonical GameState unchanged. This means that the AI agent has perfect information about all hidden cards, which is very effective but obviously constitutes cheating from the perspective of a player.
StateCombiner
Given the ability to predict game states, the AI agent must now select an
action to take in the presence of uncertainty. This is where a
StateCombiner
is used. This type picks one of the valid game states to operate on.
The StateCombiner uses an evaluation function (a StateEvaluator) to analyze game states and select the best candidate. The simplest StateCombiner is the 'worst_case' combiner, which always assumes that the worst GameState of the possible options should be used to pessimistically make decisions.
SelectionAlgorithm
Once a game state to analyze is identified, the actual search logic for
picking a game action is implemented via the
SelectionAlgorithm
trait. This implements a 'decision rule' to search the game tree and identify
the best option.
One traditional example of a selection algorithm is depth-limited tree search, where game
actions are tried sequentially, applying the algorithm recursively to pick
opponent moves and returning the best result. The
AlphaBetaAlgorithm
struct implements a more optimized version of standard
tree search using alpha-beta pruning, as described by
https://en.wikipedia.org/wiki/Alpha-beta_pruning
Another approach to move selection is selecting actions by analyzing random
games. This family of techniques is referred to as "Monte Carlo Tree Search",
and is implemented by the
MonteCarloAlgorithm
struct. Within the world of Monte Carlo methods, various algorithms exist for
identifying which moves to analyze. One standard heuristic is the UCT1
criterion, implemented by
Uct1.
StateEvaluator
The final piece of the puzzle for AI implementations is the ability to
evaluate a game state to determine whether it is favorable to the current
player. This is the role of the
StateEvaluator
trait. Given a game state and a player in the game, the evaluator returns a
negative integer if the state is worse for that player (i.e. they are losing
or have lost) and a positive integer if the state is better. A very simple
evalautor is the 'Win/Loss' function, which simply returns 1 if the player has
won the game, 0 if the game is in progress, and -1 if the player has lost.
This functions well for some algorithms, but more sophisticated evaluators can
improve AI performance significantly.
Evaluators tend to be the least generic pieces of the AI system, since their exact implementation is very game-dependent, and this is where all sorts of 'expert hueristics' for game evaluation are encoded.
AI Testing
Testing and analyzing the performance of AI implementations can be very difficult because their operations can be inherently non-deterministic and many games need to be played to identify trends. Some tools are available for working with AI Agents:
Running Matchups
Any two named AI agents can be matched against each other via the
just matchup script. For example, to compare the performance of
two agents, a command like:
just matchup \
test-alpha-beta-scores \
test-alpha-beta-heuristics \
--matches 10 \
--panic-on-search-timeout \
--move-time 30
will pit the named agents against each other for 10 matches. Refer to the
just matchup --help command for full documentation.
Running Benchmarks
Benchmarks exist for most of the major AI implementations, and new agents
should generally include benchmarks as well. These tests use the Criterion
framework to perform detailed performance analysis. Running a command like
just benchmark -- alpha_beta_search will run an AI benchmark for
the Alpha Beta Search agent.
The Game of Nim
In order to facilitate tests, the AI subsystem includes an implementation of the Game of Nim (https://en.wikipedia.org/wiki/Nim). This is useful because it applies the standard AI agent implementations to a 'known' game where it is much easier to objectively evaluate performance.
Nim is a good game to analyze because it has a very simple algorithm for perfect play, but this algorithm is difficult for agents to discover. Using large starting stack sizes the search tree for Nim can be enormous, providing a helpful way to compare AI search performance.
You can play Nim against any implemented agent, or compare the performance of
two agents using the just nim command, for example via
just nim uct1 alpha-beta --stack-size 10. The implementation runs
each agent in turn and prints out the optimal move that the agent
should take in each game state. Refer to
just nim --help for the full command information.